|
Krishnan Srinivasan I am a research scientist at Toyota Research Institute and recently completed my PhD at Stanford University, advised by Professor Jeannette Bohg and Animesh Garg. My research focuses on enabling dexterous robotic manipulation through reinforcement learning, foundation models, and large-scale simulation. My current work is building towards dexterous long-horizon generalist policies through large-scale data collection and algorithmic approaches. Email / CV / Google Scholar / GitHub / LinkedIn |

|
Research InterestsMy core research interests cover:
|
Education
PhD, Computer Science — Stanford University — June 2025
B.S., Computer Science & Mathematics — Yale University — May 2017 |
Recent PublicationsRecent work in dexterous manipulation, reinforcement learning, and foundation models for robotics. |
|
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
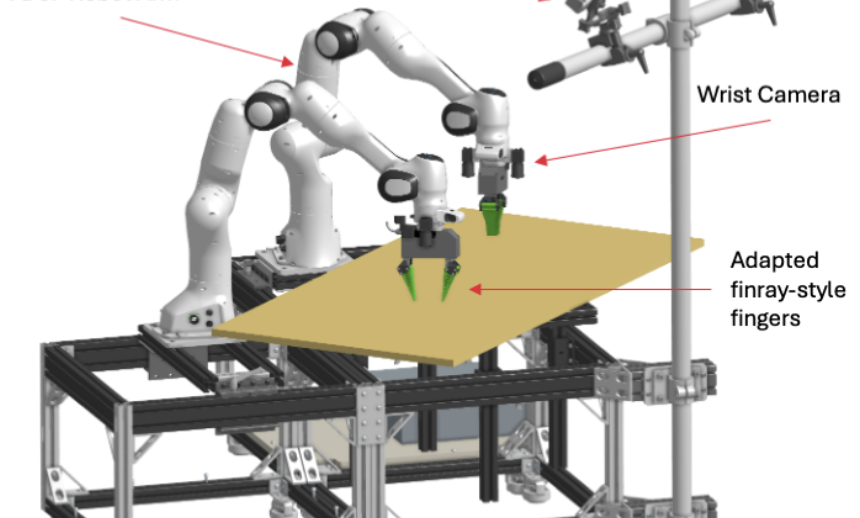
TRI LBM Team arXiv preprint, 2025 Paper / Website / BibTeX Preprint A comprehensive examination of large behavior models applied to complex dexterous manipulation tasks across multiple domains. |
|
Behavior Cloning from Suboptimal Demonstrations with Robust World Models
Krishnan Srinivasan, B. Sud, A. Garg, J. Bohg In submission, 2025 Paper / Website / BibTeX In Submission A robust approach to behavior cloning that effectively learns from suboptimal demonstrations using robust world models. |

|
ACGD: Visual Multitask Policy Learning with Asymmetric Critic Guided Distillation
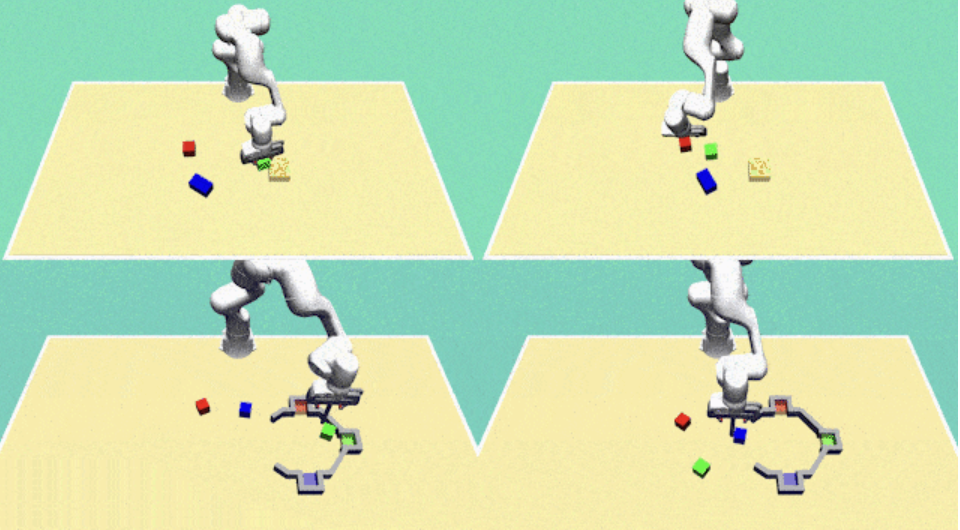
Krishnan Srinivasan, J. Xu, H. Ang, E. Heiden, D. Fox, J. Bohg, A. Garg IROS, 2025 Paper / Website / BibTeX Conference A novel approach to visual multitask policy learning using asymmetric critic guided distillation for improved performance across diverse manipulation tasks. |

|
Get a grip: Multi-finger grasp evaluation at scale enables robust sim-to-real transfer
Tyler G. W. Lum, A. Li, P. Culbertson, K. Srinivasan, A. Ames, M. Schwager, J. Bohg CoRL, 2024 Paper / Website / BibTeX Conference A scalable approach to multi-finger grasp evaluation that enables robust transfer from simulation to real-world robotic systems. |

|
DexMOTS: Learning Contact-Rich Dexterous Manipulation in an Object-Centric Task Space with Differentiable Simulation
Krishnan Srinivasan, J. Collins, E. Heiden, I. Ng, J. Bohg, A. Garg ISRR, 2024 Paper / Website / BibTeX Conference An object-centric approach to task-space policy learning that excels at contact-rich dexterous manipulation scenarios. |

|
Adaptive Horizon Actor-Critic for Policy Learning in Contact-Rich Differentiable Simulators
I. Georgiev, K. Srinivasan, E. Heiden, J. Xu, A. Garg ICML, 2024 Paper / Website / BibTeX Conference An adaptive horizon actor-critic method designed for policy learning in contact-rich environments using differentiable simulators. |
|
Borrowed from this website's template |